CLIPS
CLIPS is the abbreviated form of Corpus for the Legal Information Processing System which is built “with the mechanism underlying the Tree Model of Discourse Information” (Du, 2012).The CLIPS, with the Multimodal Information Corpus (see details in the following) as a constitutive part, can facilitate the processing of both discourse based on the information analyzed and annotated and multimodal nonverbal information that has been discoursalized (Du, 2012). The brief instructions of the corpus are demonstrated in the following.
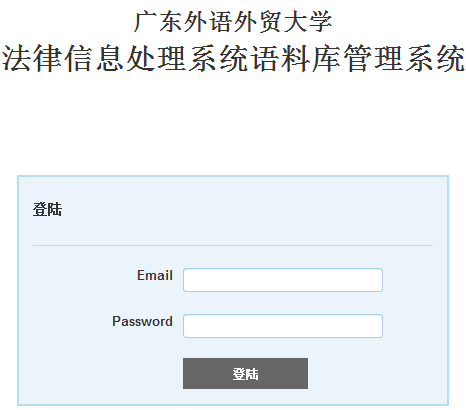
The follow is the login pagehttp://202.116.195.46:8888 where you can log in with your email and password. If it’s first time for you to use the corpus, you need to register first.
CLIPS includes three basic function modules: Corpus Annotation, Corpus Concordancing and Statistic Information which are demonstrated in the following one by one.
Basic Function Module 1: Corpus Annotation
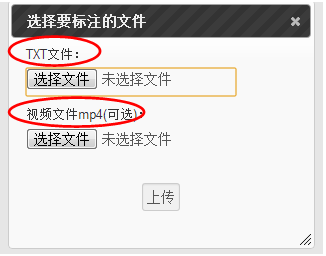
During the corpus annotation, the following window is designed for document selection, which includes both text document annotation and video document annotation (as circled in red) designed for multimodal information processing (Du, 2013).
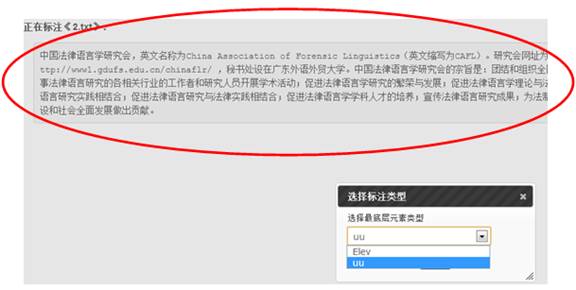
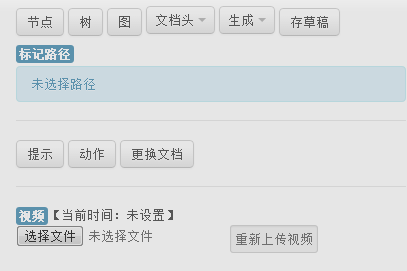
The following are the page of text document annotation and page of details for text document annotation. (Because of the space limitation, only the main parts of the pages are demonstrated)
Page of text document annotation:
Page of details for text document annotation:
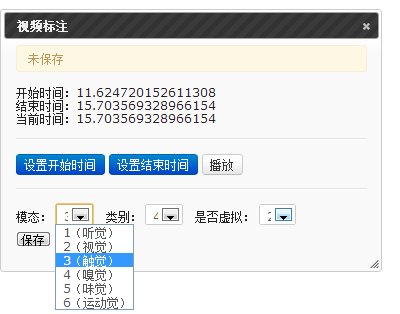
The following are the page of video annotation which includes both a video and its discoursalized document (as circled in red), and the page of details for video annotation which includes setting for start time, setting for end time and selection for modes, type and virtuality.
This part is called the Multimodal Information Corpus (MIC) which is an integral part of the CLIPS. (Du, 2012)
Page of video annotation:

Page of details for video annotation:
The following are the demonstrations of part of generated XML file and its tree structure of the document after annotation (Because of the space limitation, only part of the XML file and tree structure are demonstrated).
Part of generated XML file:
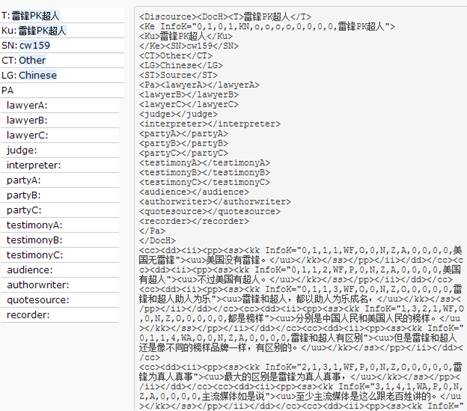
Part of generated tree structure of the document:

In the above tree structure, each information unit (Du, 2013) is coded in four numbers which can demonstrate its position in the hierarchical structure.
Basic Function Module 2: Corpus Concordancing
The following is a page of concordancing based on information unit (Du, 2007).
Concordancing example:
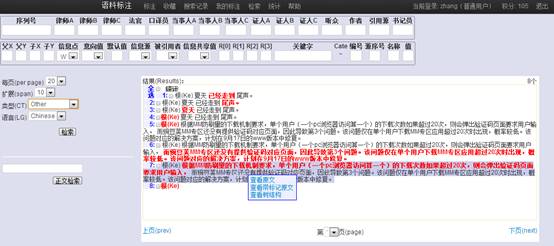
The concordancing is based on various components designed for annotation (Du, 2007).
Basic Function Module 3: Statistic Information
This function mainly includes counting of statistic information for selected corpus and statistic information for an annotated document.
Part of statistic information for selected corpus:
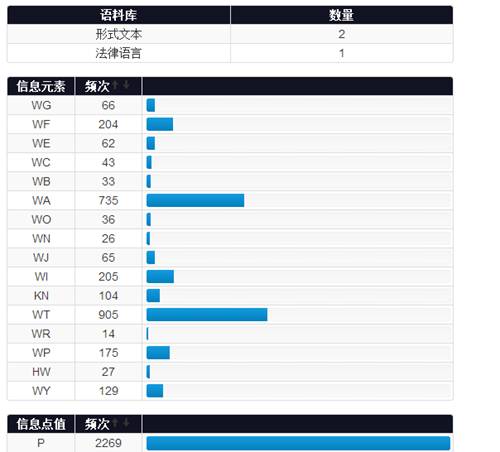
Part of statistic information for an annotated document:
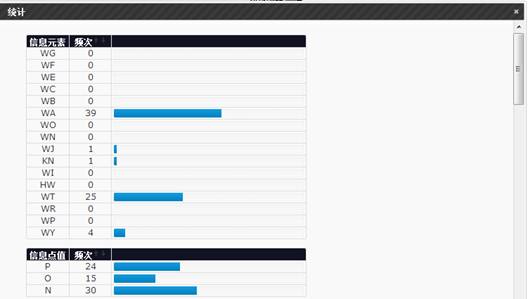
Because of the space limitation, only part of the statistic information is demonstrated in the above two figures.
Reference
Du, Jinbang. (2007). A study of the tree information structure of legal discourse. Modern Foreign Languages, 30(1), 40-50.
Du, Jinbang. (2012). Application of Multimodal Information Corpus Techniques in Legal English Teaching. International Journal of Law, Language & Discourse, 2(4), 19-38.
Du, Jinbang. (2013). How Is Multimodal Information to Be Managed in the Legal English Class? International Journal of Legal English, 1(1), 23-47.
